Instrukcja będzie się skupiać na stosowaniu różnych algorytmów w dokonania kompresji bezstratnej danych. Będziemy zajmowali się dwoma algorytmami, które realizują to zadanie — Kompresję strumieniową (RLE (Run-Length Encoding), ByteRun).
Zadania
Znaleźć 3 obrazy do przeprowadzanie analizy skuteczności kompresji (Rozmiar minimalny
800x600mogą być większe.), każdy ma reprezentować jedną z kategorii (0,1 pkt):- Rysunek techniczny,
- Wzór dokumentu, formularza lub innego dokumentu tekstowego zawierającego tekst, tabele, wykresy itd.,
- Kolorowe zdjęcie.
Napisać samodzielnie kod dokonujący kompresji strumieniowej dla omawianych metod w formie koder i dekoder. Koder powinien przyjmować jako wejście pojedynczą zamienną tablicową NumPy, a dekoder powinien zwracać zmienną w oryginalnym kształcie z identyczną zawartością danych. Pomiędzy dekoderem a koderem przekazujemy tylko jedną zmienną. Ma ona zawierać wszystkie informacje potrzebne do odtworzenia danych wejściowych (dane, kształt itd.). Kod, który będzie przekazywał te dane w inny sposób lub odtwarzał kształt poza funkcją dekodującą będzie traktowany jako źle wykonany. Do wykonania:
- RLE (0,35 pkt),
- ByteRun (0,35 pkt).
Krótkie sprawozdanie/raport z prac na podstawie obu zaimplementowanych algorytmów. (0,2 pkt)
- Proszę poświęcić paragraf sprawozdania i opisać sposób wykorzystania pamięci przez wasze implementacje. Gdzie przechowywanych jest rozmiar obrazu w każdym ze skompresowanych wektorów.
- Zaprezentować poprawność kodowania poszczególnych metod na danych testowych. Upewnić się, że dane kompresują i dekompresują się w sposób poprawny.
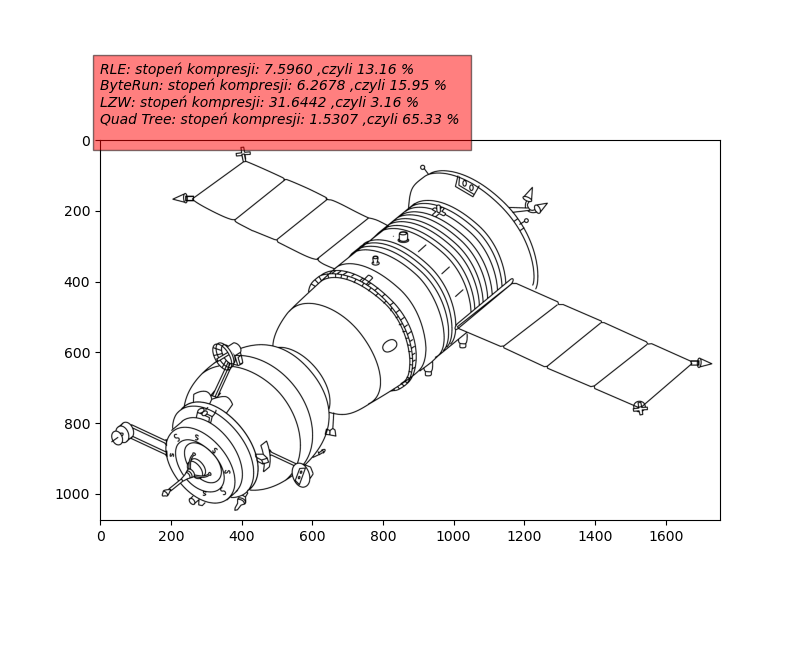
- Dla każdego z przygotowanych obrazów testowych przeprowadzić kompresję i dekompresję, każdą z metod. Udowodnić poprawność (identyczność) danych po dekompresji z danymi źródłowymi. Policzyć i zapisać skuteczność kompresji na dwa sposoby:
- jako stopień kompresji \(CR=\dfrac{|Rozmiar Przed Skompresowaniem|}{|Rozmiar Po Skompresowaniu|}\),
- jako procent oryginalnego obrazu stanowi obraz po kompresji \(PR=\dfrac{|Rozmiar Po Skompresowaniu|}{|Rozmiar Przed Skompresowaniem|}*100\).

Do oddania
- Kod źródłowy (jeden plik
.py), - Obrazy wybrane do testów,
- Krótkie sprawozdanie z obserwacjami i wynikami (format
PDF).
Kilka słów wstępu
Do funkcji kompresji wchodzi dowolna macierz numpy o dowolnej ilości wymiarów (zakładamy, że są to dane typu int), opuszcza ją jeden strumień danych skompresowanych (jedna zmienna). Do funkcji dekompresji trafia nasza skompresowana informacja, a opuszcza macierz o tym samym rozmiarze jak oryginał.
Co powinniśmy zrobić w środku?
W jaki sposób zapisać informację na temat dowolnej wymiarowości danych wykorzystując tylko \(N+1\) wartości (N to ilość wymiarów)? Mamy 2 rozwiązania na przechowywanie rozmiaru oryginalnego rozmiaru macierzy: jeden wykorzystuje listy pythona, a drugi tablice numpy:
# wersja python list
x=[len(data.shape)] #informatcja na temat ilości wymiarów
x+=list(data.shape)
# wersja NumPy
x=np.array([len(data.shape)])
x=np.concatenate([x,data.shape])Bez względu na metodę X jest początkiem danych wyjściowych, do których doklejamy naszą skompresowaną informację, żeby ją potem odkodować przy dekompresji (znaleźć nasz oryginalny kształt) wykorzystujemy to polecenie:
shape = x[1:int(x[0]+1)]
print(shape)Jak mamy już zapisany nasz rozmiar oryginału to przechodzimy do kompresji, która odbywa się na strumieniu danych, czyli musimy zrobić .flatten() i na tym spłaszczonym wektorze przeprowadzamy kompresję (RLE lub BR) i wynik tej kompresji doklejamy (appendujemy) do X i mamy naszą kompresję na wyjściu.
Przy dekompresji pobieramy informację na temat rozmiaru, a następnie dekodujemy resztę danych. i potem robimy .reshape().
Array1D=ArrayND.flatten() # spłaszczanie
ArrayND=Array1D.reshape(OG_Shape) # odtwarzanieUwagi ogólne do zadań i zapisywania danych w pamięci
Python nie jest środowiskiem, w którym łatwo oszacować, ile miejsca w pamięci zajmują konkretne zmienne. Całość jest przechowywana w sposób dynamiczny i niektóre typy danych złożonych posiadają duży narzut pamięci (np. tablice). DO sprawdzenia rozmiaru w pamięci najlepiej wykorzystać funkcję get_size opisaną kawałek dalej. Dodatkowym utrudnieniem może być fakt, że domyślnymi typami danych są int32 i float64 (lub w niektórych przypadkach 32/64-bitowe), a obrazy przechowywane w tablicach NumPy, są na przykład uint8. Dlatego porównanie ich rozmiaru w pamięci może również być zaburzone. Dlatego dla rzetelności warto nasz obraz oryginalny zrzutować do domyślnego typu w waszym środowisku:
img=img.astype(int)Domyślnie pamiętajcie, że dla każdego z algorytmów tworzycie dwie funkcje — kodującą i dekodującą. Funkcja kodująca będzie przyjmowała na wejściu domyślnie np.array dowolnego rozmiaru (nie musi być to obraz, może być to wektor wartości). Funkcja dekodująca powinna przyjąć jedną zmienną zwróconą z funkcji kodującej i na jej podstawie odtworzyć oryginalne dane. Czyli informacja na temat rozmiaru oryginału powinna również być tam umieszczona. Przykładowo pierwsza wartość skompresowanej informacji może zawierać informację o ilości wymiarów oryginału.
Jeżeli planujecie tworzyć własne struktury danych, to starajcie się pilnować objętości zmiennych w pamięci i ich narzutu. Przykładowo krotka (tuple) () zajmuje mniej miejsca w pamięci niż tablica (zwykła nie NumPy) [], ponieważ umożliwia tylko odczyt danych. Z kolei dla większych obiektów tablica NumPy może wykorzystywać dodatkowe zaimplementowane wewnątrz algorytmy optymalizacji pamięci.
Sprawdzanie rozmiaru danych w Pythonie
Dla typów prostych łatwo policzyć rozmiar zajmowanych bitów pamięci (ilość elementów pomnożona przez ilość bitów dla pojedynczego obiektu tego typu lub funkcja sys.getsizeof(obj)), jednak dla typów złożonych nie jest to takie proste. To otrzymania w dość dokładnej estymacji zajętości pamięci można wykorzystać poniższą funkcję, która w sposób rekurencyjny pozwala nam określić, jak dużo miejsca w pamięci zajmują nasze dane.
import sys
def get_size(obj, seen=None):
"""Recursively finds size of objects"""
size = sys.getsizeof(obj)
if seen is None:
seen = set()
obj_id = id(obj)
if obj_id in seen:
return 0
# Important mark as seen *before* entering recursion to gracefully handle
# self-referential objects
seen.add(obj_id)
if isinstance(obj,np.ndarray):
size=obj.nbytes
elif isinstance(obj, dict):
size += sum([get_size(v, seen) for v in obj.values()])
size += sum([get_size(k, seen) for k in obj.keys()])
elif hasattr(obj, '__dict__'):
size += get_size(obj.__dict__, seen)
elif hasattr(obj, '__iter__') and not isinstance(obj, (str, bytes, bytearray)):
size += sum([get_size(i, seen) for i in obj])
return sizeJak zrobić konsolowy pasek postępu w Pythonie
Słów kilka o pakiecie tqdm i o tym, jak można go wykorzystywać. Służy on do generowania pasków postępu dla wykonywanych pętli. Można go stosować, aby wizualizować postęp programu i nie zastanawiać się nad tym, czy program się nie zawiesił lub ile czasu jeszcze to zajmie. Zakładamy jednak, że znamy jakąś skończoną maksymalną ilość iteracji, w ramach której pętla skończy się wykonywać. Przykładowo dla przejścia pętli po wektorze, maksymalna ilość iteracji będzie równa jego długości. Możemy wyróżnić dwa wywołania:
W sposób automatyczny dla pętli for o stałym kroku. Dodajemy ją podczas definiowania pętli for jako kontener otaczający zakres wywołania naszej pętli.
from tqdm import tqdm for i in tqdm(range(0,1110)): #do somethingDla pozostałych przypadków — sterowne ręcznie. Na początku deklarujemy nasz pasek postępu (w przykładzie jako
pbar), wraz z maksymalną ilością kroków (parametrtotal). Następnie podczas każdej iteracji pętli musimy ręcznie przesunąć licznik o ilość kroków, o którą przesunęliśmy się z naszymi obliczeniami.from tqdm import tqdm with tqdm(total=max_steps) as pbar: while(...): #do something pbar.update(step)
Uwaga wywoływania funkcji print wewnątrz pętli może powodować problemy wizualne w konsoli.
Przypadki testowe
np.array([1,1,1,1,2,1,1,1,1,2,1,1,1,1])
np.array([1,2,3,1,2,3,1,2,3])
np.array([5,1,5,1,5,5,1,1,5,5,1,1,5])
np.array([-1,-1,-1,-5,-5,-3,-4,-2,1,2,2,1])
np.zeros((1,520))
np.arange(0,521,1)
np.eye(7)
np.dstack([np.eye(7),np.eye(7),np.eye(7)])
np.ones((1,1,1,1,1,1,10))